Part 1: For Those Who Love Books...
I love new books. I count down the days until favorite authors release the next shining tome of their current series -- just to make sure I can be at the bookstore bright and early to pick up a crisp, mint, first edition.
If that sounds familiar then check out my online book release tracking tools at Nexus.Alerts, featuring:
I've been using these tools for a while to track upcoming book releases and thought I'd put them together and share them. They're at Nexus.Alerts, along with the full list of almost 20 authors I'm currently tracking, plus a an Amazon storefront for your pre-ordering needs.
Part2: ...For Those Interested in the Technology
There has been a lot of talk lately about a GoogleOS. Theories include Linux distros and web desktops, either way people want a Windows killer. I think this is off track. Google aren't interested in replacing the desktop, there's no need -- why tackle MS head-on? Instead they'll subvert it, by turning desktop apps into attractive thin clients, with the heavy lifting done by online services.
Picasa and Sketchup show Google know that some things are best done on the desktop, but they also show you can leverage further benefits by linking the desktop to the web. As a desktop developer I thought I'd test this theory for myself. Below are my experiences developing Nexus.Alerts for the GoogleOS.
Creating Nexus.Alerts
Context is central to our expectations when finding information.
Take book releases; I'd expect to use a calendar to check which releases are coming up, but a Google search would be my first destination to check release dates for a specific author. If I want regular updates about new releases I'd be looking for an RSS feed. It's the same set of information but the reason I want it is a significant factor in how I expect to find it.
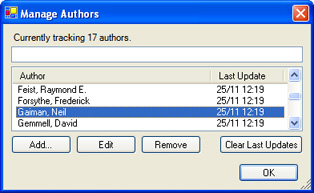
I wrote Nexus.Alerts so I could keep a close eye on book release dates. I started by writing code that regularly collects and structures upcoming book release data, the next goal was then to make it as accessible as possible.
I started with a desktop client that collects release data, displays upcoming releases, and lets me manage the authors I want to track.
It's based on a larger project (The Nexus) that I've been neglecting for months. Not coincidently, I'm at home with my laptop a lot less often than I'd like, which is why accessibility is so important.
I'm no web guru; realtime Windows application development is my thing, so I wasn't inclined to create a web app for the job. But with Google quietly developing a WebOS platform I can build a nice AJAXy site with calendars, RSS feeds, author searches, and a customized store front with Google (and a little help from Amazon) doing the heavy lifting.
The result is that my desktop client is now a light-weight server, effectively transferring my data dynamically to various Google services. In executive speak that's 'leveraging SOA' or as I like to think of it 'using other people's brains and bandwidth'. See below for how it was done.
Developing on the GoogleOS
If a Google powered WebOS becomes a reality, Google's APIs are going to be a cornerstone of their empire. They're coming along rapidly, and companies like Amazon are also producing some fine web APIs. Full details on Google's APIs and developer tools can be found on their Google code site.
The good news is decent programmers of many stripes can develop on the Google platform. The most powerful API - and their standard - is gData. gData includes Java, C++, Python, and C# client libraries; I'm a C# programmer so that's what I used.
I constructed Nexus.Alerts with these Google services:
Also at play are the following Amazon services*.
*I'm not going to focus on Amazon's offerings in this post as I'm saving them for a later one, but let me say upfront that their services are outstanding. Note to Google -- buy Amazon. No, seriously. Buy them.
Calendar
The Google Calendar API rocks. Calendar was one of the first Google services to fully leverage gData, and Google have been active in making sure it's up to snuff. There's plenty of feedback in the developer community and you can add or track issues on the gData open source project issues page.
Here's what I'm doing with Calendar:
- Whenever my desktop client/server finds a new book, it adds a new calendar entry.
- If any release details have changed it updates the calendar entry.
- If I choose to ignore a particular book, or the book has come out (therefore it's no longer the next release), it removes the calendar entry.
The result is upcoming book releases in the context of my Google calendar.
Here's a few tricky points to note for gCal development:
- There's no explicit way to 'remember' or identify a particular calendar entry. So every session the desktop app wants to update the calendar, it goes through the book list and reconciles it with the calendar entries. For this to work you need to embed an index, or identifier, into the calendar entries so you can uniquely identify them. I'm dealing with books so the ISBN is perfect. I've put it in the location field because the location field isn't relevant and so is unlikely to be messed with.
- Getting the correct url path for a calendar to use in the API is non-trivial. None of the 'address' buttons generate exactly the right string. To get the correct path you want a string in the form of: http://www.google.com/calendar/feeds/cagd3an5b8go7bkfbqfvvimhls@group.calendar.google.com/private/full You can get most of those details by clicking the XML button calendar address button on the calendar settings page. Make sure you have /private/full at the end.
- Asking for all events on a calendar defaults to one 'page' (25 by default). Either remember this and page through, or set your ItemsPerPage for your gDataFeed to int.MaxValue. I've had problems with paging (it didn't), so I'd recommend the latter.
- No analytics. Google doesn't provide any feedback telling you how many people are using your calendar. Hopefully Google will implement something like the feedback for Google base items that tells you how many people have viewed / clicked through to your item.
...And some bonus tips to take home from the experience:
- Once you're setup it's really easy. You can keep references to your entry objects, and you can call .Update() or .Delete() directly on the EventEntry objects. So once you've gone through and found the references once, further run-time changes to calendar events are quick and easy.
- You can include HTML links in the calendar description field! I've included links to Amazon to pre-order books, in future I'll probably add a link to the author's website as well.
- It's fast. Adding / removing / modifying entries is lightning quick, and the effects are seen instantly on the Calendar WebApp (You may need to hit refresh).
- As mentioned above, the client libraries are open source and available from Google's Source Code Repository. Get updates as they're implemented and become part of the community.
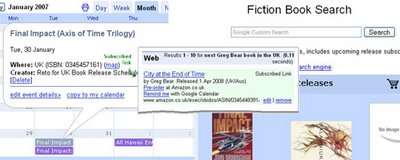
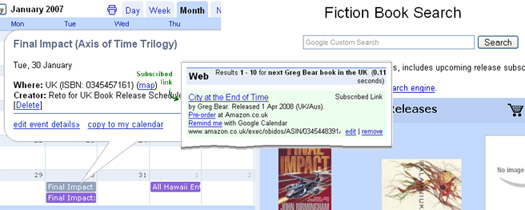
Subscribed Links (Coop)
I'm a massive fan of Coop, I believe it's Google's most underutilized and underrated service. I mean seriously, a customizable onebox!? Why won't people put useful information in there? It's simple to setup, trivial to update, and can be very effective.
Follow this link to see a Nexus.Alerts book release one-box result.
I'm using SLs to:
- Answer question like: "What's the next book by Raymond E. Feist in the UK?" (For any author in the UK/US).
- Find out the name of the next release, as well as the scheduled release date.
- Provide a link for more information plus a way to pre-order the book from Amazon.
This is probably the tool I use the most often. Perfect when I'm sitting at my desk at work (no gCal!) wondering when the next Feist book come out. 0.11 seconds later I've got an answer. Why don't more people offer this sort of service? "When's The Killers next concert?", "When's the next episode of Lost scheduled to air?". Hmmm, projects for another day :)
To make your own, start with the Subscribed Links documentation, then here's some more tips:
- Make sure your query covers the likely ways people will ask the question, but be careful not to make them too broad. A match on anything ending with next Feist book in the UK is good, but a query that must match exactly what is the name and release date for the next Feist book in the United Kingdom is much too specific. Conversely a match on anything containing Feist is far too broad.
- Coop data objects let you specify 'synonyms' for different query terms. My UK book results apply in Australia as well as the UK, so rather than enforce a match just on 'UK', I've included the synonyms: the UK, United Kingdom, Britain, England, Australia, the United Kingdom. It makes it easier for your users to trigger a 'special' search result without having to remember the exact query structure.
- You can use multiple files to provide data for one (or more) subscribed links. I have three files: The 'rules' (which defines the queries to match and that I uploaded to Google), and two separate 'dataobjects' files (one each for UK and US releases), which I host myself and update twice a day.
- Host any XML files you're planning to update somewhere you can use FTP to do so. This makes it easier to update them programmatically. That's what I'm doing, whenever book details change I rewrite and upload the dataobjects file(s). Google caches your hosted XML file so your server won't get hammered, the only drawback is the update rate. You'll have to wait for the coop spider to find your changes so it's not real-time. In my experience the spider can be unpredictable, updating changes at least once a day, sometimes every couple of hours.
- If you're automating this output be aware of XML limitations - make sure to escape special characters ('&' for example) where necessary.
- Coop dataobjects need to have unique identifiers. This goes across ALL the XML files you submit, whether they're related to each other or not. They're only used within coop internally, but to make them unique and recognizable in the XML as well I'm concatenating each author's name with a GUID.
- Include as much useful info in your result box as possible. What might you want to do when you get an answer? For me, it was looking up Amazon info on the book, pre-ordering it, or adding a reminder to my calendar; so these options are all available from the onebox.
- You're creating XML anyway so think about formatting an RSS file at the same time. I produce a feed with items for each new book, with updates if any details change. Remember that RSS feeds are often pushed out based on creation/modification times so it will probably make sense to keep track of when items were last updated so updates don't flood people with duplicate entries every day.
- Like calendars there's no subscribed links analytics. Coop will tell you how many people are subscribed, but what I'd really love to know is how many people are actually seeing my onebox results -- and how many are clicking the links?
- The structure of the onebox is tightly controlled. You get at most one link per line so make them all count. Conversely, don't use lines just because you can. If you can deliver all your data in two lines leave it at that.
Custom Search Engines
While trolling for release information I tagged the good sites with the CSE marker to create the fiction custom search engine. It's a side effect of my research, but the extra couple of seconds per search created a useful search engine. Searches using this CSE will prioritize those tagged sites, providing them with a PageRank boost within these search results.
It's worth noting that the degree of this 'boost' is customizable. You'll need to download the XML file that defines your CSE and modify the boost 'weight' for the sites deserving a greater or lesser amount of boost juice. This is really worth doing or tagging Amazon will blow every other tag out of the water. Weighting your tags will let you give Amazon a small (0.15) boost, but an obscure author's homepage can be weighted right up (with a 1.0). Dead sites and spam can have negative boost (retro?) applied (down to -1). I'll leave it at that as there's a great post on Google Blogoscoped that describes this tweaking process in detail.
Now this I really like. Google recently announced support for enforcing the use of specified Subscription Links in our CSE results. So *anyone* doing a search for 'next Greg Bear book in the UK' via the Fiction CSE will get my SL one-box like this. I love this, now we can leverage the CSE and SL onebox results without users having to commit to always letting our results influence their searches. Plus we can create links from our sites that will bring up the onebox results.
The web-based CSE setup doesn't support this yet so you'll again need to download and modify your CSE's XML file. Full instructions can be found in the CSE documentation.
Google Web Toolkit
Like the CSE, the whole Nexus.Alerts website is a side effect. I needed somewhere online to collect all the tools together and thought I'd give GWT a try while throwing something basic together.
Wow. From n00b to Web 2.0 goodness in a matter of hours. In the spirit of full disclosure I'll say that I do have a few years of basic Java programming behind me from my University days, but that fell well short of anything resembling AJAX. The Nexus.Alert website took (start to finish) about 4hrs. That might sound like a lot to any web developer worth their salt, but it would have taken me that long to create it in Google Page Creator.
I'm only 4hrs in to GWT, but here's some notes I've compiled on the way:
- It's encapsulating AJAX into a widget framework, so knowing Java syntax is
going to help you here. Really -- it'll help a lot. As will any sort of programming background. - The documentation is doco-lite. The samples are great, but there's not a lot more there. There does seem to be a pretty large community using the tools though.
- Download and use Eclipse for your development work. Eclipse is an IDE for Java, and features things like code completion and syntax highlighting. GWT offers full Eclipse support so there's no reason not to use it (unless you're too h4rdc0rz). I really recommend this.
- Google's GWT site gives good instructions for creating new projects from scratch for Eclipse but skips how to create an Eclipse project based on a sample. Easiest way is to create a new project, then move everything in the samples 'src' folder into your new project.
- The Kitchen Sink sample has a GMail style interface with buttons on the side acting like tab pages. But none of the other samples specifically address how to do this! Use the Kitchen Sink sample, the classes you'll want to check out are SinkItem and SinkList.
- Note that if you want the Google looking colors and styles you'll need to use their sample CSS files. The KitchenSink.css takes care of everything I've needed so far.
- Start with one widget, then build on top of that. GWT builds up really well and it's easy to follow what's happening if you master one new widget at a time. I started with the GMail style Sinks / Sinklist, then added the HistoryListener (back button support), and finally added country tabs for the calendar and bookstore pages. Popup boxes are next!
Some Final Thoughts on the GoogleOS
The success of any OS relies heavily on the ability of users to write code for it.
You think Windows is so popular because it's the *best*? Good lord. Marketing and monopolies aside, a big reason people choose Windows is because the software they want to use is available on that platform. That software's there due to the relative ease of writing code that works the same on (more or less) any Windows box.
As Google positions itself as a WebOS, their APIs are going to be coming under very close scrutiny by very picky people. Their ability to provide robust, predictable, easy to use APIs (and quickly respond to developer feedback) will go a long way in determining their success against more traditional desktop rivals.




 It's a really useful service that lets you view articles on timelines to get a real sense for the flow and context of world news, giving current news articles an instant sense of history.
It's a really useful service that lets you view articles on timelines to get a real sense for the flow and context of world news, giving current news articles an instant sense of history.